

A OpenAI iniciou a distribuição de uma arquitetura de memória aprimorada para o ChatGPT, projetada para manter e conectar o contexto de diferentes sessões de conversação. Com a novidade, a taxa de retenção de dados factuais subiu de 67,9% para 82,8%, de acordo com relatórios internos da empresa.
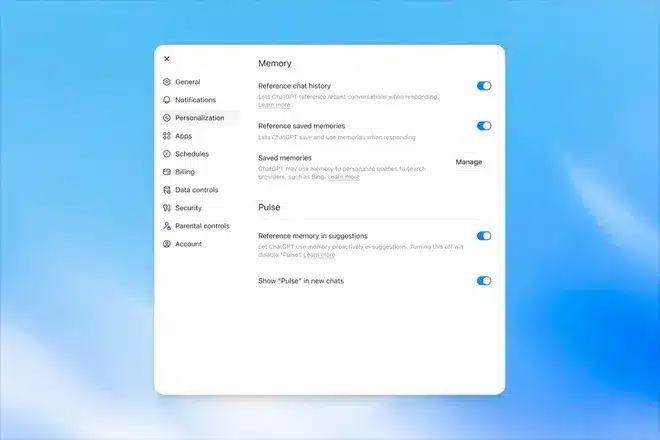
O primeiro estágio dessa estrutura foi lançado em abril de 2024, quando o sistema passou a armazenar memórias salvas mediante comandos diretos do usuário. Em seguida, em abril de 2025, a companhia expandiu o mecanismo com um processo de segundo plano chamado Dreaming, capaz de ler todo o histórico de interações e atualizar automaticamente as preferências e registros dos projetos.
Desempenho e custos computacionais
Nos testes conduzidos entre 2025 e 2026, o ChatGPT apresentou avanços em três indicadores principais:
- Retenção de dados factuais: precisão na recuperação de informações específicas cresceu de 67,9% para 82,8%.
- Cumprimento de restrições: aderência a diretrizes e limites estabelecidos pelo usuário saltou de 55,3% para 71,3%.
- Consistência temporal: filtragem de conteúdos desatualizados e manutenção de informações vigentes passou de 52,2% para 75,1%.
A nova infraestrutura também analisa o tempo de validade dos registros para descartar menções obsoletas — como planos de viagem já concluídos — e oferece ao usuário um painel centralizado para gerenciar as memórias. Nesse painel, é possível excluir, editar ou definir cenários de aplicação automática de contextos pelo assistente.
Além disso, otimizações no código de processamento reduziram em cinco vezes o custo computacional do sistema Dreaming, permitindo que a funcionalidade seja disponibilizada a todos os usuários da modalidade gratuita. Os assinantes dos planos Plus e Pro nos Estados Unidos receberam aumento na capacidade de retenção de caracteres, com liberação gradual prevista para os demais mercados e perfis Free e Go.

Imagem: Imagem ilustrativa
Com as melhorias, a OpenAI reforça o compromisso de tornar o ChatGPT mais eficiente na gestão de informações, mantendo a precisão e o contexto em conversas de longa duração.
Com informações de Hardware


